ANNIS Query Language - AQL
Nodes and Edges
AQL is based on the concept of searching for node elements and edges between them. A search is formulated by defining each token, non-terminal node or annotation being searched for as an element. An element can be a token (simply text between quotes: "dogs" or else tok="dogs") or an attribute-value pair (such as lemma="dog", or optionally with a namespace: tiger:cat="PP"). Note that different corpora can have completely different annotation names and values - these are not specified by ANNIS. Underspecified tokens or nodes in general may be specified using tok and node respectively.
Once all elements are declared, relations between the elements (or edges) are specified which must hold between them. The elements are referred back to serially using variable numbers, and linguistic operators bind them together, e.g. #1 > #2 meaning the first element dominates the second in a tree or graph. Operators define the possible overlap and adjacency relations between annotation spans, as well as recursive hierarchical relations between nodes. Some operators also allow specific labes to be specified in addition to the operator (see the operator list below).
The following example, a query searching for German sentences with topicalized objects (i.e. with the word order object-verb-subject), illustrates these ideas in practice:
| node & pos="VVFIN" & cat="S" & node & | //two nodes, a finite verb and a sentence node (S) |
| #3 >[tiger:func="OA"] #1 & | //S dominates node 1 with label OA |
| #3 >[tiger:func="SB"] #4 & | //S dominates node 4 with label SB |
| #3 > #2 & | //S dominates (>) the verb |
| #1 .* #2 & | //node 1 precedes (.*) the verb |
| #2 .* #4 | //the verb precedes (.*) node 4 |
Try out this query in the pcc2 corpus in ANNIS3
Shortcuts
Starting in ANNIS 3.1.0, you can also use shortcuts to define the relations between query nodes. You can specify the operator that applies between two nodes directly between those nodes. For example, the following two queries are equivalent:
| cat="NP" & cat="PP" & #1 > #2 | |||||||||||||||||||||||||||||
| or: | |||||||||||||||||||||||||||||
| cat="NP" > cat="PP" | |||||||||||||||||||||||||||||
| NP#cat="NP" & | //a nominal phrase which we will call 'NP' |
| #PP1#cat="PP" . PP2#cat="PP" & | //two consecutive prepositional phrases named PP1 and PP2 |
| #NP > #PP1 & | //the NP node dominates PP1 |
| #NP > #PP2 & | //the same NP node also dominates PP2 |
Metadata
To specify metadata conditions which must apply to matches, add key-value pairs preceded by the reserved prefix meta::. Metadata may apply to corpora, sub-corpora, or individual documents within a corpus. For example, the following query finds sequences of two consecutive adverbs in sports documents (Genre="Sport"):
| pos="ADV" & pos="ADV" & | //two adverb tags |
| #1 . #2 & | //adverb 1 precedes adverb 2 directly |
| meta::Genre="Sport" | //the metadatum Genre must have the value "Sport" |
Try out this query in the pcc2 corpus in ANNIS3
Unary Operators
Two operators refer to only one matching element, instead of specifying a relationship between two elements: tokenarity and arity. The tokenarity operator specifies how many tokens should be covered by the matching element, whereas the arity operator determines the amount of directly dominated children the matched node should have. For example, the following query searches for nominal phrases that dominate exactly 4 nodes:
| cat="NP" & | //a syntactic category 'NP' for 'nominal phrase' |
| #1:arity=4 | //this node should have exactly 4 children |
Try out this query in the pcc2 corpus in ANNIS3
Query Builder
In order to facilitate the formulation of complex queries, a graphical query builder allows users to define their search in a graph. This reflects the nodes and edges in the query directly but gives a more intuitive view of the elements and relations being searched for.
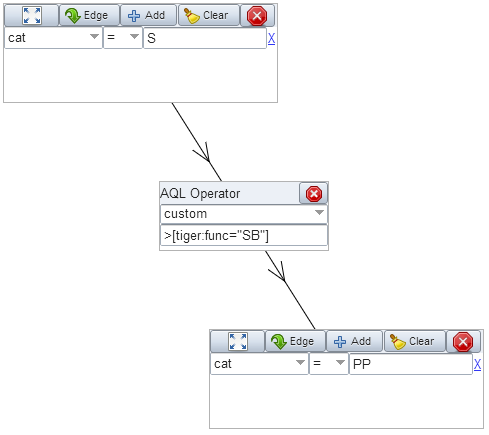
|
RegEx Support
ANNIS supports RegEx natively in all token, annotation, edge label and metadata searches. In the query builder simply select ~ instead of = as the comparison operator. When entering a query manually use = but replace the double quotes around annotation and token values with slashes, e.g. lemma=/d.g/ finds "dog" and "dig".
Example Queries
Beginning with ANNIS 3.0.0, the possibility to include user-defined example queries within a corpus distribution has been added. The example queries can be entered in a separate file, called example_queries.tab within the relANNIS corpus folder. For more information on how to add example queries to your corpus, see the ANNIS User Guide on the documentation page.
Operators
AQL currently includes the following operators:
| Operator | Description | Illustration | Notes | ||||||||||||||||||||||||||
. | direct precedence | For non-terminal nodes, precedence is determined by the right-most and left-most terminal children. In corpora with multiple segmentations the layer on which consecutivity holds may be specified with .layer | |||||||||||||||||||||||||||
.* | indirect precedence | For specific sizes of precedence spans, .n,m can be used, e.g. .3,4 - between 3 and 4 token distance; the default maximum distance for .* is 50 tokens. As above, segmentation layers may be specified, e.g. .layer,3,4 | |||||||||||||||||||||||||||
> | direct dominance | | B |
A specific edge type may be specified, e.g. >secedge to find secondary edges. Edge labels are specified in brackets, e.g. >[func="OA"] for an edge with the function 'object, accusative' |
||||||||||||||||||||||||||
>* |
indirect dominance | | ... | B |
For specific distance of dominance, >n,m can be used, e.g. >3,4 - dominates with 3 to 4 edges distance |
||||||||||||||||||||||||||
_=_ | identical coverage | B |
Applies when two annotations cover the exact same span of tokens | ||||||||||||||||||||||||||
_i_ |
inclusion | B |
Applies when one annotation covers a span identical to or larger than another | ||||||||||||||||||||||||||
_o_ |
overlap | BBB |
For overlap only on the left or right side, use _ol_ and _or_ respectively |
||||||||||||||||||||||||||
_l_ |
left aligned | AAA BB |
Both elements span an area beginning with the same token | ||||||||||||||||||||||||||
_r_ |
right aligned | AA BBB |
Both elements span an area ending with the same token | ||||||||||||||||||||||||||
| == | value identity | The value of the annotation or token A is identical to that of B (this operator does not bind, i.e. the nodes must be connected by some other criteria too) | |||||||||||||||||||||||||||
| != | value difference | The value of the annotation or token A is different from B (this operator does not bind, i.e. the nodes must be connected by some other criteria too) | |||||||||||||||||||||||||||
->LABEL |
labeled pointing relation |
| A labeled, directed relationship between two elements. Annotations can be specified with ->LABEL[annotation="VALUE"] | ||||||||||||||||||||||||||
->LABEL * |
indirect pointing relation |
| An indirect labeled relationship between two elements. The length of the chain may be specified with ->LABEL n,m for relation chains of length n to m | ||||||||||||||||||||||||||
>@l |
left-most child | / | \ B x y | |||||||||||||||||||||||||||
>@r |
right-most child | / | \ x y B |
|||||||||||||||||||||||||||
| $ | Common parent node | / \ A B |
|||||||||||||||||||||||||||
| $* | Common ancestor node | | ... / \ A B |
|||||||||||||||||||||||||||
| #x:arity=n | Arity |
x / | \ 1 ... n |
Specifies the amount of directly dominated children that the searched node has | ||||||||||||||||||||||||||
| #x:tokenarity=n | Tokenarity |
x ... / \ 1 ... n |
Specifies the length of the span of tokens covered by the node | ||||||||||||||||||||||||||
| #x:root | Root |
___ x ... |
Specifies that the node is not dominated by any other node within its namespace | ||||||||||||||||||||||||||